Tokens Are Memory: Context Window Management for Production LLM Systems
Tokens are the unit of cost and latency in every LLM system you build. If you've ever profiled a slow database query or tracked memory allocation in a hot code path, you already have the mental model — you just need to apply it one layer up.
Every call to GPT-4o, Claude 3.5, or any hosted LLM is billed and rate-limited in tokens. Input tokens. Output tokens. Context tokens. They're the CPU cycles of the AI layer, and if you're not counting them, you're flying blind in production.
Why Token Economics Mirror Memory Management
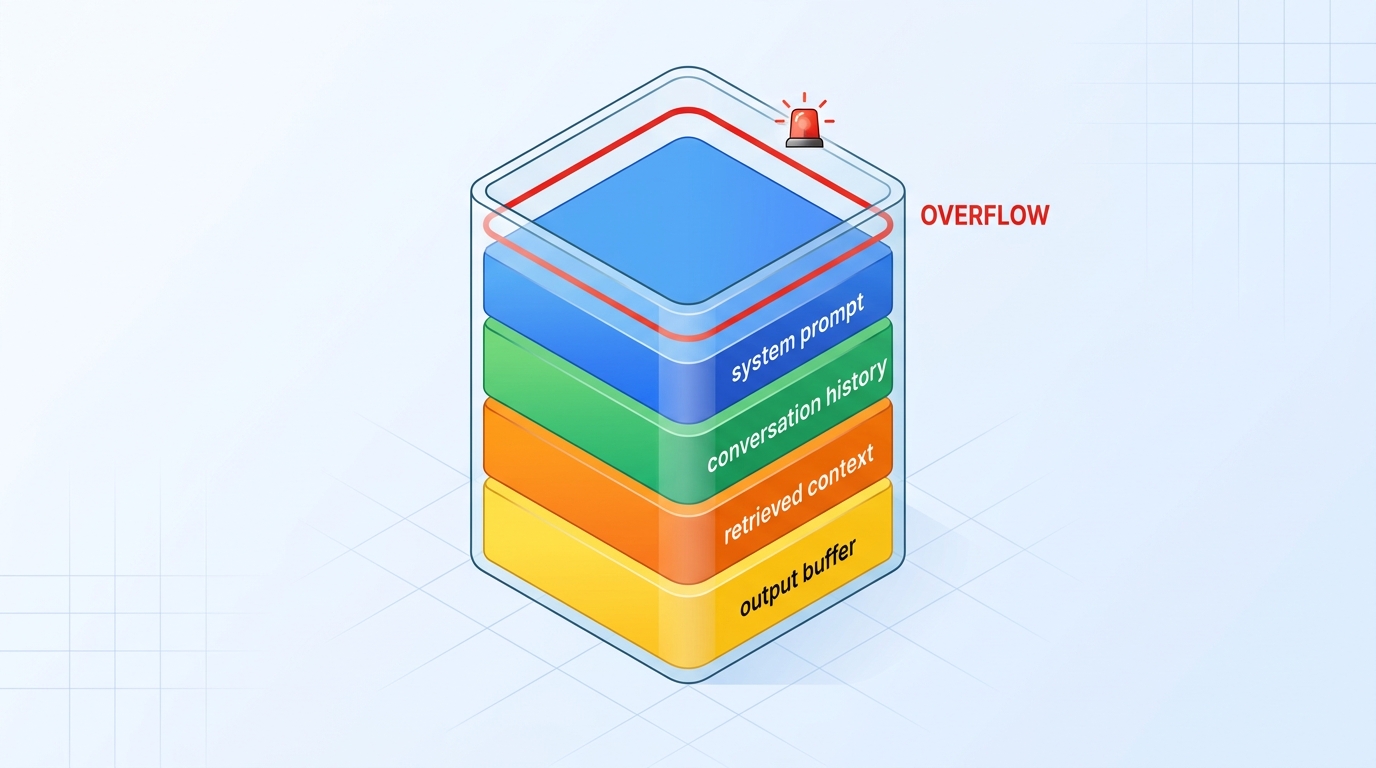
Think of the context window as a fixed-size buffer — not unlike a request payload limit or an L1 cache. The model can only "see" what fits inside it. Everything outside the window doesn't exist to the model at inference time.
Here's the constraint map for a typical RAG application:
- System prompt: 200–800 tokens (your instructions, persona, formatting rules)
- Retrieved context chunks: 500–4,000 tokens per chunk × N chunks
- Conversation history: grows unboundedly with every turn
- User query: usually small, 20–150 tokens
- Output buffer: tokens the model needs to generate a useful response
A GPT-4o context window is 128K tokens. That sounds enormous until your RAG pipeline retrieves 10 chunks at 1,500 tokens each, your system prompt is 600 tokens, and you're on turn 8 of a multi-turn conversation. Suddenly you're at 20K+ tokens and climbing — and you haven't written a line of output yet.
The engineers who get burned aren't the ones who don't know what tokens are. They're the ones who never implemented a budget.
Counting Tokens Accurately with tiktoken
Don't estimate. Count. OpenAI's tiktoken library gives you exact token counts before you make an API call — the same tokenizer the model uses.
import tiktoken
def count_tokens(text: str, model: str = "gpt-4o") -> int:
enc = tiktoken.encoding_for_model(model)
return len(enc.encode(text))
def build_context_within_budget(
system_prompt: str,
history: list[dict],
retrieved_chunks: list[str],
user_query: str,
model: str = "gpt-4o",
max_context_tokens: int = 120_000,
output_buffer: int = 2_000,
) -> dict:
token_budget = max_context_tokens - output_buffer
used = count_tokens(system_prompt) + count_tokens(user_query)
# Fit as many history turns as possible, most recent first
trimmed_history = []
for turn in reversed(history):
turn_tokens = count_tokens(turn["content"])
if used + turn_tokens > token_budget * 0.4: # cap history at 40% of budget
break
trimmed_history.insert(0, turn)
used += turn_tokens
# Fill remaining budget with retrieved chunks
fitted_chunks = []
for chunk in retrieved_chunks:
chunk_tokens = count_tokens(chunk)
if used + chunk_tokens > token_budget:
break
fitted_chunks.append(chunk)
used += chunk_tokens
return {
"system": system_prompt,
"history": trimmed_history,
"context": fitted_chunks,
"query": user_query,
"total_tokens_used": used,
}
This pattern enforces a hard budget before the API call is ever made. You decide the allocation strategy — history vs. context tradeoff — rather than letting the model silently truncate or the API throw a context_length_exceeded error at 2 AM.
The Token Budget Allocation Framework
There's no universal split, but here's a starting heuristic for a RAG chatbot:
| Slot | Allocation | Notes |
|---|---|---|
| System prompt | Fixed, ~5% | Optimize once, freeze it |
| Conversation history | Up to 30% | Trim oldest turns first |
| Retrieved context | Up to 55% | Most impactful for answer quality |
| Output buffer | ~10% | Never skip this — truncated outputs are silent failures |
Adjust based on your use case. A summarization pipeline needs almost no history. A customer support agent needs more history and less retrieved context.
Anthropic's approach: Claude and token counting
Claude models use a different tokenizer than GPT models, so tiktoken won't give you accurate counts for Anthropic's API. Use the Anthropic Python SDK's client.messages.count_tokens() method instead — it makes a lightweight API call that returns an exact count without generating a response. Budget logic stays the same; just swap the counting function.
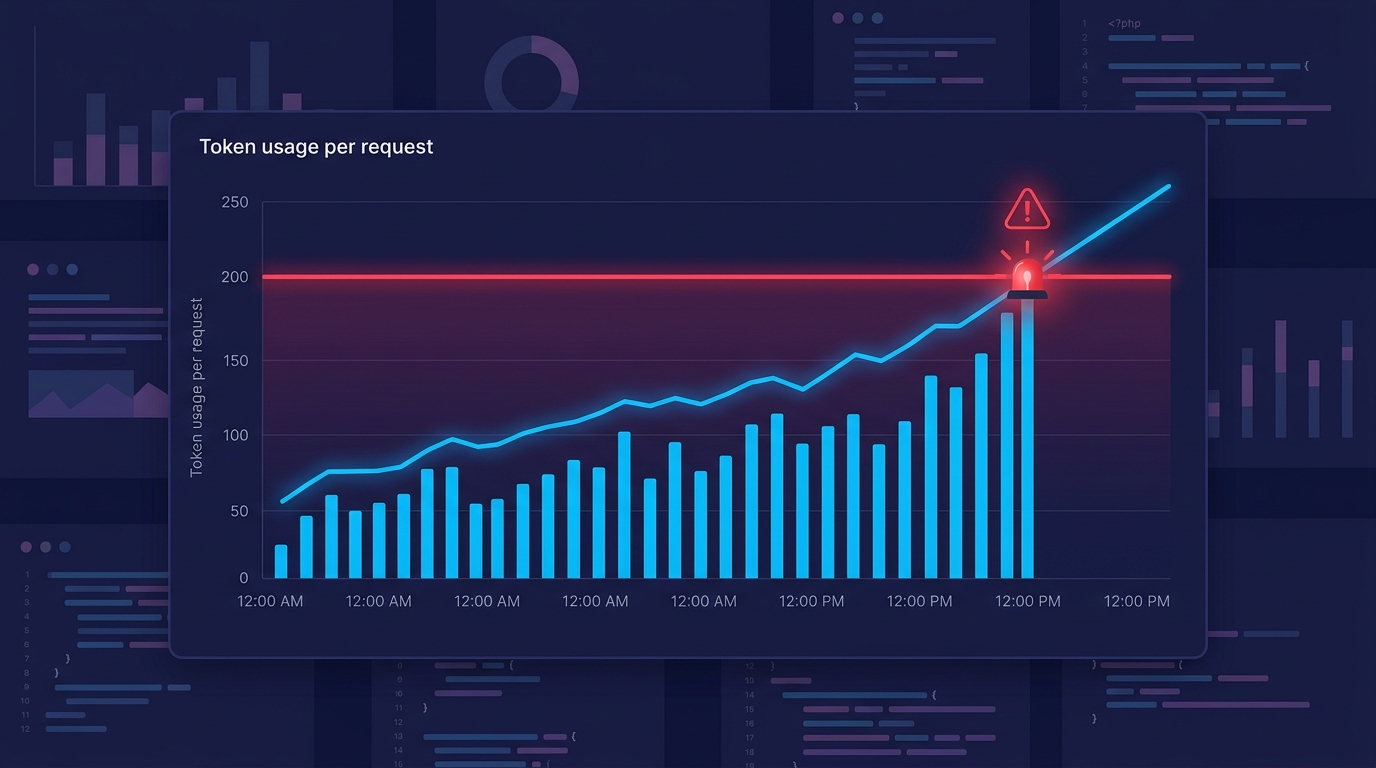
The Gotcha: Silent Truncation and Quality Degradation
The most dangerous failure mode isn't an error — it's silent quality degradation. Many LLM APIs will truncate your input if it exceeds the context window rather than throwing an exception. Your application keeps running. Your logs look clean. Your answers quietly get worse because the model never saw the most relevant retrieved chunks.
Always implement token counting at the application layer, not as an afterthought. Log total_tokens_used per request. Set alerts when you're consistently hitting 80%+ of your budget. That's the signal your retrieval strategy or prompt needs to be tightened.
Takeaway
Tokens are a finite, billable resource with hard ceilings — treat your context window the way you'd treat heap memory: count it, budget it, and never assume there's more than you can see.