
RAG Chunking Strategy: How Chunk Size, Overlap, and Metadata Shape Retrieval Quality
If your RAG system retrieves documents that look relevant but produce mediocre answers, the problem is almost certainly upstream of your LLM. It lives in your chunking pipeline.
Chunking is the step where you split source documents into fragments before embedding and storing them. Most engineers pick a chunk size early in development, wire it up, and move on. That number — often a default from whatever library they grabbed first — quietly shapes every retrieval result the system ever produces.
This post covers the three levers that matter most: chunk size, overlap, and metadata.
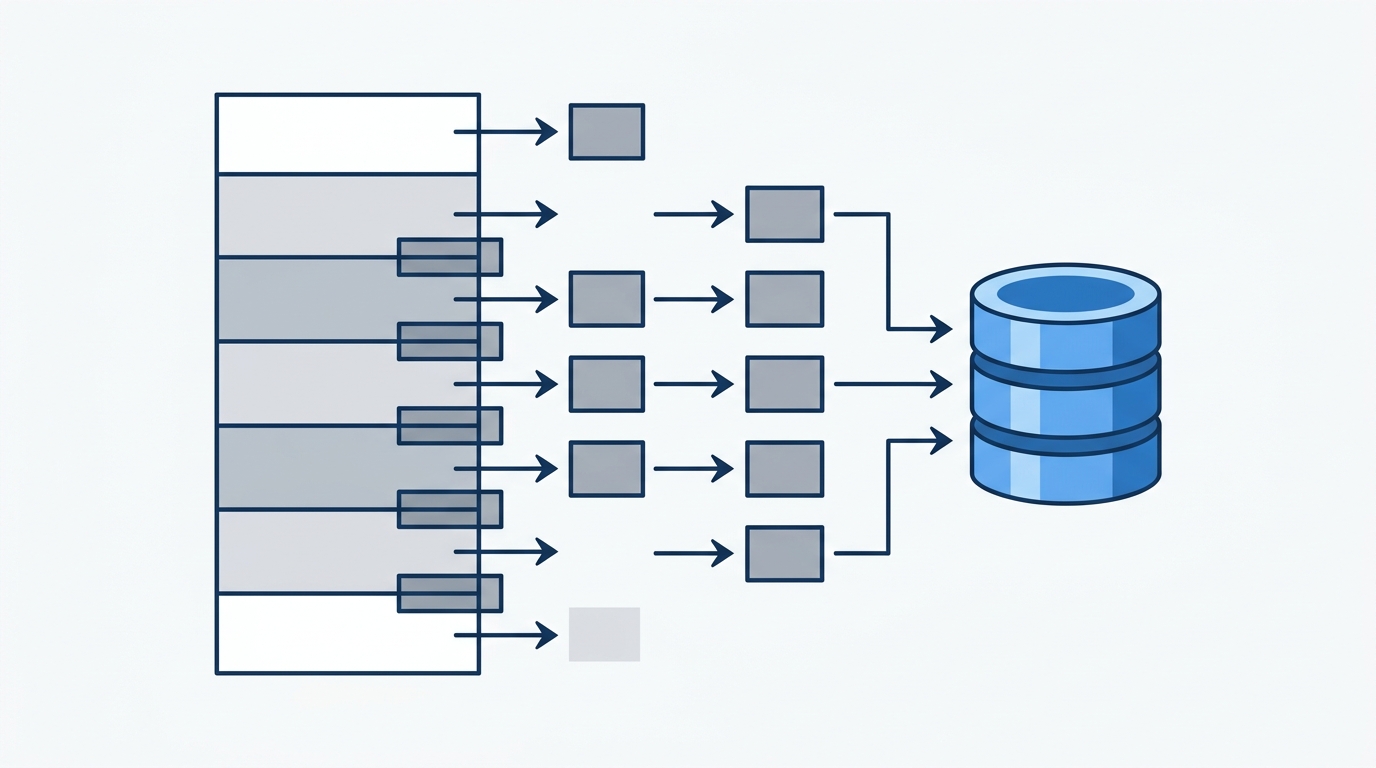
Chunk Size Is a Retrieval Precision Dial
Chunk size controls the granularity of what gets embedded and stored. Every size choice is a tradeoff:
- Larger chunks (512–1024 tokens): Preserve surrounding context, which helps the LLM generate coherent answers. But they reduce retrieval precision — a large chunk matching on one sentence will drag in several unrelated sentences alongside it, consuming context window space and potentially diluting the answer.
- Smaller chunks (128–256 tokens): Improve retrieval precision — you get tighter semantic matches. But they fragment meaning. A single concept split across two chunks may never be retrieved together, causing incomplete or contradictory answers.
The practical starting point for most document corpora is 256–512 tokens. From there, tune based on your document structure:
| Document Type | Recommended Chunk Size |
|---|---|
| Dense technical docs / legal text | 512–1024 tokens |
| FAQ / support articles | 128–256 tokens |
| Mixed / general knowledge base | 256–512 tokens |
If your queries tend to be narrow and specific ("What is the cancellation policy?"), smaller chunks win. If they're broad and synthesizing ("Summarize the compliance requirements for GDPR Article 17"), larger chunks preserve the context needed to answer well.
Chunk Overlap Prevents Semantic Boundary Cuts
When you split a document at a fixed token boundary, you will inevitably cut sentences — and sometimes entire arguments — in half. Chunk overlap is the mechanism that prevents this.
Overlap means the tail of chunk N is repeated at the head of chunk N+1. If your chunk size is 512 tokens and your overlap is 10%, the last 51 tokens of each chunk reappear at the start of the next.
The practical math:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # tokens per chunk
chunk_overlap=51, # ~10% overlap
length_function=len, # swap for tiktoken if using token-based sizing
separators=["\n\n", "\n", ".", " ", ""] # respect natural boundaries first
)
docs = splitter.create_documents([raw_document_text])
The separators list is important: RecursiveCharacterTextSplitter tries each separator in order, only falling back to the next if the chunk is still too large. This means it will try to split on paragraph breaks before sentences, and sentences before words — preserving semantic coherence where possible.
Overlap guidelines by document type:
- Narrative / prose: 15–20% overlap (ideas span paragraphs)
- Structured / tabular: 5–10% overlap (sections are more self-contained)
- Code: 0% overlap at function boundaries, or use an AST-aware splitter

Metadata Extraction at Chunk Time
Here's the lever most engineers skip entirely: embedding metadata into each chunk at write time.
Every chunk you store in your vector database can carry structured metadata alongside its embedding vector. This metadata enables filtering before similarity search — dramatically improving retrieval relevance without increasing chunk count or re-embedding anything.
def build_chunk_with_metadata(chunk_text, doc):
return {
"text": chunk_text,
"metadata": {
"source": doc.filename,
"section": extract_nearest_header(chunk_text, doc),
"doc_type": doc.category, # e.g., "policy", "tutorial"
"created_at": doc.created_at.isoformat(),
"language": detect_language(chunk_text)
}
}
At query time, you can pre-filter on doc_type or created_at before running the embedding similarity search. Most vector databases (Pinecone, Weaviate, Qdrant, pgvector) support metadata filtering natively.
Why this matters: Without metadata filtering, your similarity search runs across your entire corpus. With it, you can scope retrieval to "only policy documents updated in the last 90 days" before a single cosine distance is computed. That's not just a quality improvement — it's a latency and cost reduction.
The Gotcha: Re-Chunking Is Expensive — Get It Right Early
Changing your chunk size after you've embedded and stored a large corpus means re-embedding everything. At scale, that's a non-trivial compute and API cost. The decisions you make in your chunking pipeline are sticky.
The correct approach is to benchmark chunk sizes on a representative query set before committing. Build a small evaluation harness: take 20–30 real queries, retrieve with three different chunk configurations, and score answer quality manually or with an LLM-as-judge. The difference between 256 and 512 tokens is often dramatic and immediately visible.
What is semantic chunking, and when should you use it?
Semantic chunking is an alternative to fixed-size chunking where chunk boundaries are determined by embedding similarity rather than token count. You embed each sentence independently, then group consecutive sentences into chunks as long as their embedding similarity stays above a threshold. When similarity drops sharply, you start a new chunk.
This produces chunks that are more semantically coherent — each chunk represents one idea rather than an arbitrary token window. Libraries like LangChain's SemanticChunker and LlamaIndex implement this.
Tradeoff: Semantic chunking is significantly more expensive at index time (you're embedding every sentence individually, not just each chunk). It also produces variable-length chunks, which can complicate downstream token budget management. Use it when retrieval quality is paramount and you have the compute budget. For most production systems starting out, well-tuned fixed-size chunking with proper overlap is a better first investment.
Takeaway
Chunk size, overlap percentage, and metadata extraction are not implementation details — they are the primary controls on retrieval quality in a RAG system, and they should be treated with the same deliberateness as any other architectural decision.