
OpenAI vs Anthropic in Production: A Backend Engineer's Decision Framework (Not Another Benchmark Post)
You're three days into designing a new AI feature. You've got a prototype working with one provider's playground. Now your tech lead asks: "Which API are we actually building on?"
This is the moment most engineers default to name recognition or whichever API they hit first. That's a mistake you'll pay for at scale. Here's the framework to make this decision deliberately — before your abstraction layer is baked into six services.

The Four Axes That Actually Matter
Benchmark scores measure capability in controlled conditions. Production systems care about four different things:
- Cost at your actual usage volume
- Latency under your response-time budget
- Rate limits against your traffic shape
- Context window size as an architectural constraint
Let's walk through each.
Cost: Run the Numbers on Your Pattern, Not the Price Card
At the time of writing, OpenAI's gpt-4o and Anthropic's claude-3-5-sonnet are the primary workhorses for production use cases. The sticker prices are close enough to be misleading — what matters is your input/output token ratio.
LLM APIs charge input and output tokens at different rates, and output tokens are almost always more expensive. If your feature generates long responses (reports, summaries, code), the output cost dominates. If you're doing classification or structured extraction, input cost dominates.
Both providers also offer prompt caching — a mechanism where repeated prefixes in your prompt (system prompts, static context, RAG chunks) are cached server-side and charged at a dramatically reduced rate. For RAG applications with large, stable system prompts, this can cut costs by 60–80% on cache hits.
# Rough cost estimator — plug in your actual numbers
def estimate_monthly_cost(
requests_per_day: int,
avg_input_tokens: int,
avg_output_tokens: int,
input_price_per_1m: float, # e.g., 3.00 for claude-3-5-sonnet
output_price_per_1m: float, # e.g., 15.00 for claude-3-5-sonnet
cache_hit_rate: float = 0.0,
cached_tokens: int = 0,
cached_price_per_1m: float = 0.30,
) -> float:
daily_requests = requests_per_day
# Tokens that miss the cache
uncached_input = avg_input_tokens - (cached_tokens * cache_hit_rate)
input_cost = (uncached_input * daily_requests / 1_000_000) * input_price_per_1m
cache_cost = (cached_tokens * cache_hit_rate * daily_requests / 1_000_000) * cached_price_per_1m
output_cost = (avg_output_tokens * daily_requests / 1_000_000) * output_price_per_1m
return (input_cost + cache_cost + output_cost) * 30 # monthly
# Example: Support chatbot, 10k requests/day
monthly = estimate_monthly_cost(
requests_per_day=10_000,
avg_input_tokens=1_200,
avg_output_tokens=300,
input_price_per_1m=3.00,
output_price_per_1m=15.00,
cache_hit_rate=0.7, # 70% of requests reuse the system prompt
cached_tokens=800, # 800-token system prompt gets cached
cached_price_per_1m=0.30,
)
print(f"Estimated monthly cost: ${monthly:.2f}")
Run this with both providers' current pricing before committing. The gap may surprise you in either direction depending on your workload.
Latency: Where the Architectures Diverge
OpenAI's gpt-4o is generally faster for short-to-medium context requests — time-to-first-token (TTFT) tends to be lower, which matters enormously for streaming UI experiences. Anthropic's Claude models have improved significantly but still lag slightly on TTFT for comparable model tiers.
Where Anthropic pulls ahead: long-context tasks. If you're sending 50K+ tokens of context (large documents, extended conversation history, big RAG payloads), Claude's architecture handles this more gracefully — both in instruction adherence and in maintaining coherent reasoning across the full window.
The practical split:
- User-facing, low-latency features (autocomplete, short Q&A, chat): lean toward OpenAI
- Background processing, document analysis, complex reasoning: Claude's long-context handling is a real advantage
Rate Limits and API Stability
This is the axis most engineers ignore until it bites them in production.
Both providers tier their rate limits by spend history. New accounts start with conservative limits — often low enough to cause problems during a traffic spike or launch event. Key considerations:
- Request rate limits (RPM) matter for bursty workloads
- Token rate limits (TPM) matter for high-volume, long-context use cases
- Batch APIs exist on both platforms for async, non-real-time processing at lower cost — use these for any workload that doesn't need synchronous responses
Anthropically, both providers have had notable outages. Design for this regardless of which you choose.
Context Window as an Architectural Decision
Claude 3.5 Sonnet offers a 200K token context window. GPT-4o offers 128K. These aren't just specs — they change how you architect your RAG pipeline.
A larger context window means:
- You can stuff more retrieved chunks before hitting limits
- You may be able to skip chunking entirely for small-to-medium documents
- Long conversation histories don't require aggressive summarization strategies
A smaller window forces tighter chunking discipline, which can actually improve retrieval precision. It's not strictly worse — it's a different constraint that shapes your design.
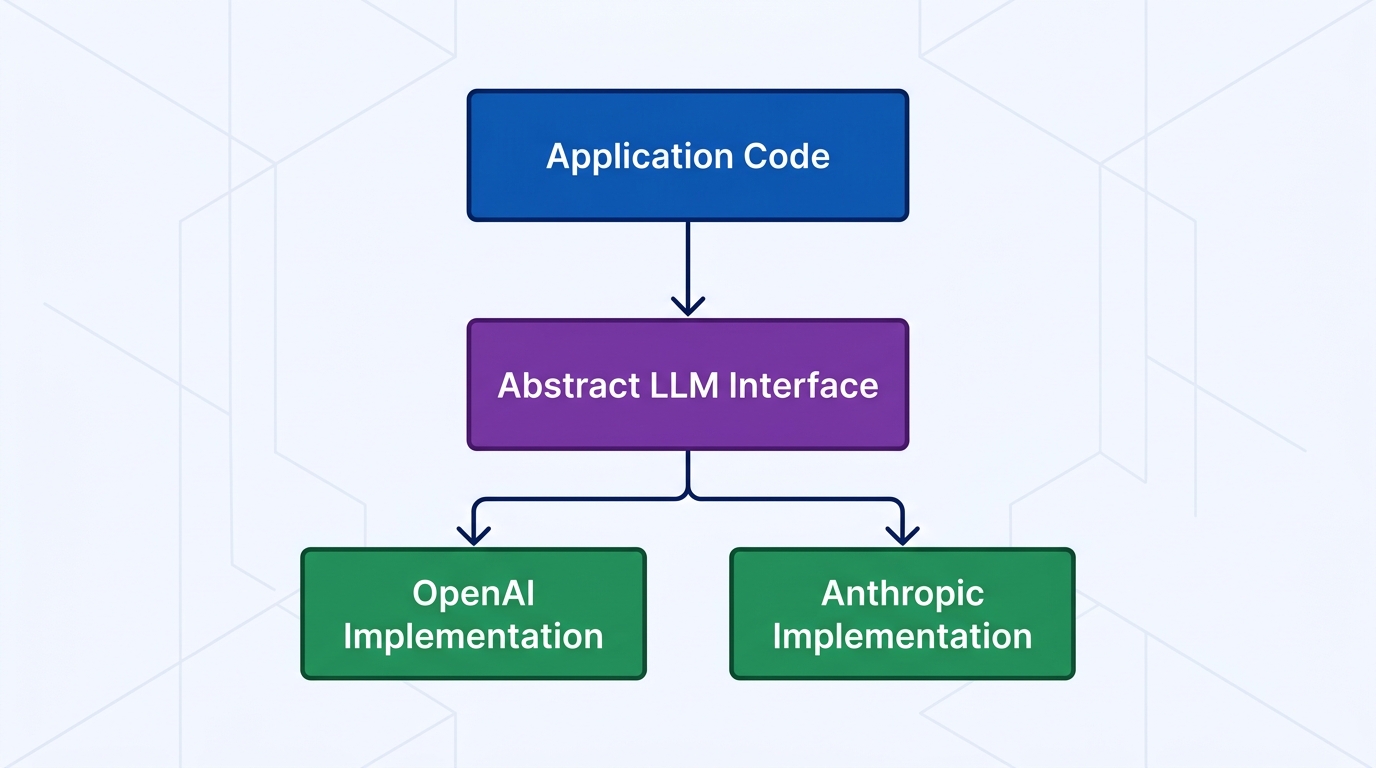
The Abstraction Layer You Should Build on Day One
Here's the mistake: building directly against one provider's SDK throughout your codebase. Switching costs are real — not just the API calls, but prompt formats, error handling, retry logic, and response parsing.
Build a thin abstraction layer early:
from abc import ABC, abstractmethod
from dataclasses import dataclass
from typing import AsyncIterator
@dataclass
class LLMResponse:
content: str
input_tokens: int
output_tokens: int
model: str
class LLMProvider(ABC):
@abstractmethod
async def complete(
self,
system_prompt: str,
user_message: str,
max_tokens: int = 1024,
) -> LLMResponse:
...
class OpenAIProvider(LLMProvider):
def __init__(self, model: str = "gpt-4o"):
from openai import AsyncOpenAI
self.client = AsyncOpenAI()
self.model = model
async def complete(self, system_prompt, user_message, max_tokens=1024):
response = await self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message},
],
max_tokens=max_tokens,
)
return LLMResponse(
content=response.choices[0].message.content,
input_tokens=response.usage.prompt_tokens,
output_tokens=response.usage.completion_tokens,
model=self.model,
)
class AnthropicProvider(LLMProvider):
def __init__(self, model: str = "claude-3-5-sonnet-20241022"):
import anthropic
self.client = anthropic.AsyncAnthropic()
self.model = model
async def complete(self, system_prompt, user_message, max_tokens=1024):
response = await self.client.messages.create(
model=self.model,
system=system_prompt,
messages=[{"role": "user", "content": user_message}],
max_tokens=max_tokens,
)
return LLMResponse(
content=response.content[0].text,
input_tokens=response.usage.input_tokens,
output_tokens=response.usage.output_tokens,
model=self.model,
)
This pattern costs you maybe two hours upfront and saves you days of refactoring if you ever need to swap providers, run A/B tests between them, or add a fallback.
⚠️ The Gotcha
Don't treat the provider decision as permanent based on today's pricing and capabilities. Both OpenAI and Anthropic update model versions, pricing, and rate limits frequently. The abstraction layer above isn't just good engineering hygiene — it's insurance against a landscape that will look different in six months.
The Takeaway
Choose your LLM provider based on your actual token usage pattern, latency requirements, and context window needs — then protect that decision with an abstraction layer that makes switching a configuration change, not a refactor.