
Handling Hallucinations and Unreliable Outputs in Production LLM Systems
Handling hallucinations in a production LLM system is less like debugging a deterministic function and more like managing a junior developer who sometimes invents APIs that don't exist — confidently, fluently, and at scale.
The hard part isn't knowing hallucinations happen. Every engineer who has spent 20 minutes with an LLM has seen it confidently cite a paper that doesn't exist or describe a function with the wrong signature. The hard part is building systems that catch, contain, and recover from these failures before they reach your users.
This post gives you a mental model for where hallucinations come from, then walks through the layered mitigation strategy that production teams actually use.
Why LLMs Hallucinate (The Short Version)
LLMs don't retrieve facts — they generate the most statistically likely next token given a context. When the model lacks reliable training signal for a specific fact, it doesn't say "I don't know." It generates a plausible-sounding continuation.
There are two distinct failure modes you need to design for:
- Intrinsic hallucination — the model contradicts its own context or the source documents you provided
- Extrinsic hallucination — the model generates content that can't be verified against any provided source (often a knowledge cutoff or training gap issue)
In RAG systems specifically, a third failure mode appears: retrieval-induced hallucination, where the model is given retrieved chunks that are slightly off-topic, and it tries to synthesize an answer anyway rather than admitting the context is insufficient.
Understanding which failure mode you're dealing with changes which mitigation you reach for.
Layer 1: Prompt-Level Defenses
The cheapest mitigation happens before the model generates anything. Prompt design can meaningfully reduce hallucination rates.
Ground the model to a context window. If you're building a RAG system, instruct the model explicitly to only use the provided context — and to say so when it can't answer from that context.
SYSTEM_PROMPT = """
You are a support assistant. Answer questions using ONLY the information
provided in the context below. If the context does not contain enough
information to answer the question, respond with:
"I don't have enough information to answer that from the available documentation."
Do not use prior knowledge. Do not infer beyond what is stated.
"""
This won't eliminate hallucinations, but it shifts the model's behavior toward abstention rather than confabulation — which is a much better failure mode for production.
Use structured output formats. Asking for JSON or a structured response forces the model to commit to discrete fields, which makes downstream validation tractable.
OUTPUT_INSTRUCTION = """
Respond in JSON with this exact shape:
{
"answer": "<your answer>",
"confidence": "high" | "medium" | "low",
"source_quoted": "<direct quote from context that supports your answer>"
}
"""
The source_quoted field is particularly useful — it forces the model to anchor its answer to something in the context, and gives you a verifiable string to check programmatically.
Layer 2: Output Validation
Once you have an output, you need to evaluate it before returning it to the user. There are three practical approaches here, and they work best in combination.
2a. Semantic Similarity Scoring
If you're using RAG, you can score how semantically similar the generated answer is to the retrieved chunks. A very low similarity score is a signal the model may have drifted from the source material.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
def check_grounding(answer: str, context_chunks: list[str], threshold: float = 0.4) -> bool:
answer_embedding = model.encode(answer, convert_to_tensor=True)
chunk_embeddings = model.encode(context_chunks, convert_to_tensor=True)
scores = util.cos_sim(answer_embedding, chunk_embeddings)
max_score = scores.max().item()
return max_score >= threshold # False = likely hallucination
This is fast, cheap, and surprisingly effective at catching answers that have no grounding in the retrieved documents.
2b. LLM-as-a-Judge
For higher-stakes outputs, use a second LLM call to evaluate the first. This pattern — sometimes called "LLM-as-a-judge" — is now common in production systems at companies like Anthropic and OpenAI's internal evals teams.
import anthropic
client = anthropic.Anthropic()
def judge_answer(question: str, context: str, answer: str) -> dict:
prompt = f"""You are a factual accuracy evaluator.
Question: {question}
Context provided: {context}
Generated answer: {answer}
Evaluate whether the answer is fully supported by the context.
Respond in JSON: {{"supported": true/false, "reason": "<brief explanation>"}}"""
response = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=200,
messages=[{"role": "user", "content": prompt}]
)
import json
return json.loads(response.content[0].text)
Use a smaller, faster model for the judge to keep latency and cost reasonable. Claude 3.5 Haiku or GPT-4o-mini work well here.
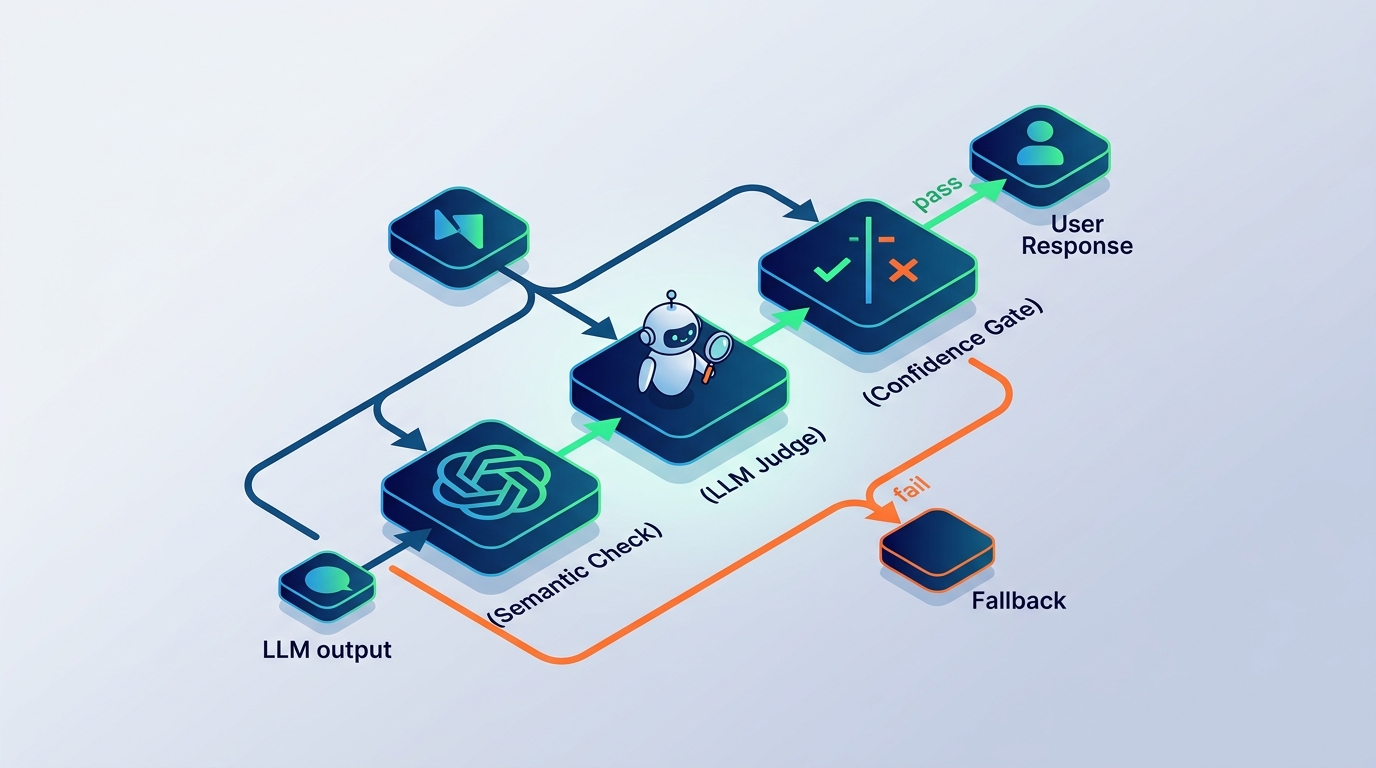
2c. Confidence Gating
If your structured output includes a confidence field (as shown in Layer 1), you can route low-confidence answers to a fallback path rather than returning them directly.
def route_response(response: dict) -> str:
if not response.get("supported", True):
return fallback_response()
if response["confidence"] == "low":
return escalate_to_human_or_fallback(response["answer"])
return response["answer"]
This is not a perfect signal — models are often overconfident — but it catches a meaningful slice of low-quality outputs.
Layer 3: System-Level Patterns
Individual prompt tricks and output checks are necessary but not sufficient. At the system level, there are architectural decisions that materially reduce hallucination exposure.
Retrieval quality is upstream of generation quality. Most hallucinations in RAG systems trace back to poor retrieval — wrong chunks, insufficient context, or chunks that are semantically close but factually different from what the question needs. Investing in your retrieval pipeline (better chunking, hybrid search, reranking) reduces the hallucination surface area more than any prompt engineering trick.
Implement a fallback hierarchy. Don't let the LLM be the only path to an answer. A well-designed system looks like:
- Try retrieval-augmented generation with grounding check
- If grounding check fails → return a "I found related information but can't confirm a direct answer" response
- If retrieval returns nothing → return a clean "I don't have information on this" rather than letting the model speculate
Log everything for offline evaluation. You cannot improve what you don't measure. Log the question, the retrieved chunks, the generated answer, and any validation scores. Run periodic offline evals against a labeled dataset to track your hallucination rate over time. Tools like LangSmith and Braintrust make this tractable without building custom infrastructure.

The Gotcha: Validation Adds Latency and Cost
The most common mistake engineers make when implementing these patterns is applying all of them to every request. LLM-as-a-judge adds a full model call to your critical path. Semantic similarity scoring adds embedding computation. Stack these naively and your p95 latency doubles.
The right approach is tiered validation based on risk:
- Low-stakes outputs (summarization, formatting) → prompt-level defenses only
- Medium-stakes outputs (Q&A, recommendations) → semantic similarity check
- High-stakes outputs (medical, legal, financial, account-affecting actions) → LLM-as-a-judge + human review queue
Match your validation overhead to the actual cost of getting it wrong.
What about fine-tuning to reduce hallucinations?
Fine-tuning can reduce hallucination rates for specific domains by giving the model stronger priors about what accurate responses look like in your context. However, it doesn't eliminate the problem — fine-tuned models still hallucinate, especially on edge cases outside the fine-tuning distribution.
Fine-tuning is a longer-term investment that complements (not replaces) runtime detection. For most production teams, the layered detection approach described above delivers faster ROI.
If you do fine-tune, include examples where the correct answer is "I don't know" or "the context doesn't contain this information" — this trains the model toward abstention rather than confabulation on uncertain inputs.
Takeaway
Hallucination mitigation in production LLM systems is a defense-in-depth problem: prompt-level grounding reduces the frequency, output validation catches what gets through, and system-level architecture limits the blast radius when both fail.